
Meistern Sie die Herausforderungen der High-Content-Zellanalyse mit KI/maschinellem Lernen
Die künstliche Intelligenz (KI) erobert viele Aspekte des modernen Lebens, von autonom fahrenden Autos bis hin zu sprachgesteuerten persönlichen Assistenten und sogar in der Gestaltung von Kunst. Aber es ist die Anwendung in der Wissenschaft und im Gesundheitswesen, in der die Vorteile von KI wirklich hervorstechen. Eine dieser Anwendungen ist die Biobildanalyse oder High-Content-Analyse (HCA).
Da HCA gewachsen ist und als quantitatives Werkzeug für die biomedizinische Forschung immer mehr an Bedeutung gewonnen hat, wächst der Anwendungsbereich weiter und beschränkt sich nicht mehr auf eine endliche Liste gut definierter Assays, die in biologischen Standardmodellen durchgeführt werden. Um dieser zusätzlichen Komplexität Rechnung zu tragen, wurde ein großer Schwerpunkt auf die Verbesserung der Flexibilität und Leistung von Analysemethoden durch KI oder maschinelles Lernen gelegt. Tatsächlich gibt es viele Beispiele, bei denen es traditionelle Methoden für Anwendungen in vielen wissenschaftlichen Disziplinen übertrifft.
Bis vor kurzem wurde die Verwendung dieser fortschrittlicheren Methoden des maschinellen Lernens weitgehend Forschungsgruppen vorbehalten, die über ausreichenden Zugang zu spezialisierten Fähigkeiten in der Datenwissenschaft und der Entwicklung benutzerdefinierter Software verfügen. Hier bieten wir eine kurze Einführung in die KI und untersuchen, wie neue, schlüsselfertige Softwarelösungen für maschinelles Lernen es Forschern ermöglichen, alle Inhalte in einem Bild zu nutzen und eine umfassendere Analyse durchzuführen, während sie gleichzeitig die Komplexität für den Anwender verringern.
Was ist KI oder maschinelles Lernen?
Maschinelles Lernen ist eine Form der KI (künstliche Intelligenz). Deep Learning. Neuronale Netzwerke. All dies sind etwas andere Begriffe für KI, die das Oxford-Wörterbuch folgendermaßen definiert:
„Die Theorie und Entwicklung von Computersystemen, die in der Lage sind, Aufgaben durchzuführen, die normalerweise menschliche Intelligenz erfordern, wie visuelle Wahrnehmung, Spracherkennung, Entscheidungsfindung und Übersetzung zwischen Sprachen.“
Im Wesentlichen stellt KI jede Intelligenz dar, die von Maschinen demonstriert wird, die kognitive Funktionen imitieren, die wir normalerweise mit menschlichen Köpfen assoziieren würden, wie Lernen, Problemlösung und Argumentation. Maschinelles Lernen ist eine Technik, die von Wissenschaftlern verwendet wird, um Computern zu ermöglichen, schnell aus Daten zu lernen.
Überwindung der Komplexität eines HCA-Arbeitsablaufs
Ein High-Content-Screening oder HCA-Arbeitsablauf wie unser ImageXpress Confocal HT.ai ist im Kern nichts anderes als eine automatisierte Mikroskopie, gefolgt von einer automatisierten Bildanalyse. Während der Aufnahmephase werden Bilder von mehreren Proben in Mikrotiterplatten aufgenommen. Dies kann die Sammlung einer großen Menge an Bilddaten beinhalten, wenn Sie beispielsweise versuchen, ein wirksames Medikament zu verstehen, um einen erkrankten Phänotyp zu retten.
Der Analyseteil des Arbeitsablaufs kann in zwei Teile unterteilt werden: Bildanalyse und Downstream-Analyse. Während der Bildanalyse werden bestimmte Merkmale und Messungen aus dem Bild extrahiert und in ein Format umgewandelt, in dem die statistische Analyse angewendet werden kann. Bei der Downstream-Analyse werden alle hochdimensionalen Daten erfasst und in einem Format destilliert, das Wissenschaftler interpretieren und Schlussfolgerungen ziehen können, sodass sie mit der nächsten Phase ihres Forschungsprojekts fortfahren können.
Die heutige Welt des High-Content-Screenings ist viel umfassender, wenn es um das Verständnis und die Beschreibung eines Phänotyps geht. Anstatt ein einzelnes Merkmal zu extrahieren oder ein Verhältnis einiger verschiedener Messungen durchzuführen, extrahieren Forscher Tausende von Merkmalen für jede Zelle in einem Bild. Dies erfordert nicht, dass sie wissen, was das Ziel für ein Medikament ist, oder dass sie die Funktion eines Gens vollständig verstehen. Es sucht einfach nach Unterschieden zwischen zwei verschiedenen Bedingungen, indem es den gesamten informationsreichen Inhalt im Bild nutzt.
Da die Komplexität bestimmter Assays weiter zunimmt und wir mehr Informationen aus einer einzelnen Zelle extrahieren, werden die Daten noch überwältigender. Wie machen wir also Sinn für all diese Informationen und destillieren sie auf etwas, das umsetzbar ist?
Herkömmliche Bildanalysemethoden können besonders aufwendig und zeitaufwendig sein, wenn sie manuell oder sogar halbautomatisch durchgeführt werden. Aufgrund der schwierigen und extrem detaillierten Art der Aufgabe besteht immer die Möglichkeit menschlicher Fehler und Voreingenommenheit. Wenn man dann noch die sich wiederholenden, langwierigen und oft arbeitsintensiven Abläufe hinzunimmt, bietet sich die Möglichkeit an, maschinelles Lernen anzuwenden. KI beseitigt jede Variation, jeden menschlichen Fehler und jede Verzerrung von Mensch zu Mensch, wodurch die Datenqualität und das Vertrauen verbessert sowie der Arbeitsablauf und die Effizienz optimiert werden.
Überwindung menschlicher Voreingenommenheit
Einer der wichtigsten Vorteile des maschinellen Lernens bei HCA, der eine besondere Aufmerksamkeit verdient, ist die Fähigkeit, menschliche Voreingenommenheit zu überwinden. Bei der Untersuchung großer Datensätze sind Menschen anfällig für ein gut beschriebenes Phänomen, das als „unbeabsichtigte Blindheit“ bezeichnet wird. Hier werden unerwartete Beobachtungen bei der Durchführung anderer aufmerksamkeitsbedürftiger Aufgaben unbemerkt.
Nachdem Sie zum Beispiel zuvor einen bestimmten Zellphänotyp und eine bestimmte Reaktion im Detail untersucht haben, suchen Sie möglicherweise unbeabsichtigt nach denselben Anzeichen, wenn Ihnen ein großer, komplexer Datensatz mit vielen Variablen und Messgrößen präsentiert wird. Dadurch könnten Sie dann ein anderes subtiles oder unerwartetes Merkmal übersehen, das ebenfalls biologische Relevanz hat.
Maschinelles Lernen hilft dabei, diese Schwachstelle zu überwinden und führt eine völlig unvoreingenommene Klassifizierung durch, mit dem Potenzial, unerwartete, wertvolle Ergebnisse zu liefern.
Anwendung von maschinellem Lernen auf die Objektsegmentierung
Zuverlässige quantitative Daten sind für jeden Downstream-Schritt im HCA-Arbeitsablauf von entscheidender Bedeutung, wobei die Segmentierung der erste ist. Die Segmentierung ist der Prozess, bei dem die Objekte von Interesse (z. B. Organellen) aus Bildern extrahiert und dann deren Merkmale quantifiziert werden. Im Grunde genommen ist dies der erste Schritt bei der Umwandlung von Bildpixeln in numerische Daten.
Die Segmentierung kann eine Herausforderung darstellen, insbesondere bei der Arbeit mit herkömmlichen Signalverarbeitungsmethoden, die darauf ausgelegt sind, sich auf ein Objekt zu konzentrieren. In mikroskopischen Bildern von Zellen oder Geweben werden Objekte in der Regel überfüllt oder verklumpt. Darüber hinaus haben sie unterschiedliche Größen und Formen. Häufig kommt es zu einem schlechten Signal-Rausch-Verhältnis, einem geringen Kontrast und einer schlechten Bildauflösung. Ganz zu schweigen davon, dass es aufgrund chemischer Störungen oder natürlicher Heterogenität im Zelltyp selbst eine hohe phänotypische Variabilität geben kann.
Um die Herausforderungen der Segmentierung anzugehen, können Deep-Learning-Algorithmen auf den Bildanalyse-Teil des HCA-Arbeitsablaufs angewendet werden. Die IN Carta™ Image Analysis Software umfasst beispielsweise ein Deep-Learning-basiertes Modul mit dem Namen SINAP, das für die Verwendung mit einer Vielzahl von Daten entwickelt wurde.
Da SINAP Deep Learning verwendet, kann es große Schwankungen im Aussehen der Proben berücksichtigen, die sich aus den untersuchten Testbehandlungen ergeben. Indem sichergestellt wird, dass jede Behandlung mit einem gleichwertigen Maß an Genauigkeit segmentiert wird, können die in diesem Schritt extrahierten Informationen zuverlässig verwendet werden, um Behandlungen in nachfolgenden Analyseschritten zu vergleichen.
Beispiele für das IN Carta SINAP Modul:
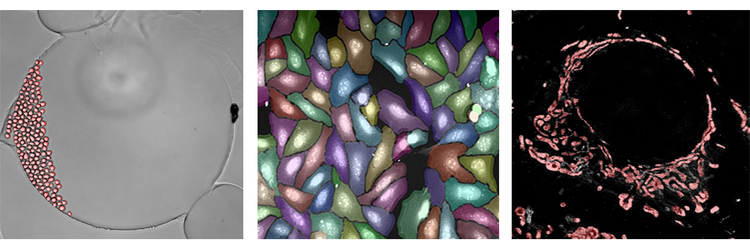
Oben sind Beispiele für den SINAP Deep-Learning-Algorithmus aufgeführt, der auf drei völlig unterschiedliche Datensätze angewendet wird. Die Hellfeldanalyse ist in der Abbildung ganz links dargestellt. Bei der Analyse handelt es sich wirklich um eine Einzelzellsegmentierung mit der Zeit, bei der beobachtet wird, wie sich Lebendzellen teilen und bewegen. Die mittlere Abbildung zeigt die Segmentierung eines Cell-Painting-Assays. Obwohl die Zellen überfüllt sind, ist SINAP in der Lage, die Objekte mit hoher Genauigkeit zu segmentieren. Die Abbildung ganz rechts stammt von einem Bild mit hoher Auflösung von Mitochondrien. Auch wenn dieser Inhalt völlig anders ist, kann derselbe Arbeitsablauf und Algorithmus verwendet werden, um einzelne Mitochondrien in den Datenquellen und dem Bild zu untersuchen. In allen drei Fällen können Sie die Segmentierung mit dem SINAP Deep-Learning-Algorithmus präziser und zuverlässiger abschließen.
Anwendung von maschinellem Lernen auf die Objektklassifizierung
Da Sie versuchen, so viel Inhalt wie möglich in einem HCA-Arbeitsablauf zu nutzen, ist es wichtig sicherzustellen, dass der Inhalt ein gewisses Maß an Qualität aufweist, bevor Sie den Downstream-Analyseschritt erreichen. Hier kommt die Objektklassifizierung ins Spiel. Die Objektklassifizierung ist der Prozess der Aufteilung von Datensätzen in Unterpopulationen basierend auf dem Phänotyp (z. B. zelluläre Morphologie, subzelluläre Lokalisierung, Expressionsniveau spezifischer Marker).
Es ist möglich, ein Klassifikator-Tool zu verwenden, um relevante Merkmale manuell auszuwählen und Klassen zuzuweisen, dies gilt jedoch nur für unkomplizierte phänotypische Änderungen, die auf ein paar Maßnahmen basieren. Sie können beispielsweise eine Zellzyklusphase basierend auf der Intensität des Kernfarbstoffs bestimmen oder lebende oder tote Zellen in einem Überlebensfähigkeits-Assay klassifizieren. Für alles Komplexere, das eine erweiterte Reihe von Funktionen mit sich bringt, wird die Verwendung von KI zur Objektklassifizierung zu einer besseren Option.
Beim maschinellen Lernen muss der Anwender keine Messgrößen oder Schwellenwerte mehr manuell auswählen. Stattdessen wird diese Aufgabe dem Computer zugewiesen. Der menschliche Anwender stellt die Computerbeispiele verschiedener Zellklassen zur Verfügung. Der Computer stellt heraus, wie man zwischen diesen Klassen unterscheidet. Im Wesentlichen lernt der Computer die am besten geeigneten Funktionen und hat den zusätzlichen Vorteil, dass er die richtige Kombination von Funktionen erlernen kann.
Die IN Carta-Software umfasst auch ein trainierbares Objektebenen-Klassifikatormodul mit der Bezeichnung Phenoglyphs. Das Phenoglyphs-Modul verwendet die von SINAP extrahierten Informationen, um Objekte mit einem ähnlichen optischen Erscheinungsbild zu gruppieren. Auf diese Weise kann beurteilt werden, ob eine Behandlung einen günstigen Phänotyp hervorruft, und es ist sogar möglich, Rückschlüsse auf die zugrundeliegenden Mechanismen zu ziehen. Durch den Einsatz des maschinellen Lernens können alle visuellen Merkmale gleichzeitig analysiert werden, um das komplexe Regelset zu optimieren, das für die Zuordnung von Objekten zu ihrer ordnungsgemäßen Gruppe erforderlich ist. Dieser hochgradig multivariate und datengesteuerte Ansatz ist weitaus besser in der Lage, subtile phänotypische Unterschiede zu lösen, und ist robuster gegen die Zuordnung von Objekten zu einer falschen Gruppe.
Die vier Schritte des Trainings des IN Carta Phenoglyphs Moduls:
- Cluster: Das Modul wählt automatisch Messungen aus, die während der Segmentierung berechnet werden, um natürliche Gruppierungen in den Daten, sogenannte Cluster, ohne menschliche Verzerrungen zu erstellen.
- Etikett: Der Benutzer wählt alle gültigen Klassen (mindestens zwei) aus und markiert sie für die Einstufung und Schulung.
- Rangfolge: Das Modul klassifiziert die Liste der Maßnahmen, die zur Partitionierung von Objekten in Klassen verwendet werden, und bietet die Möglichkeit, Maßnahmen mit redundanten Informationen oder geringen Auswirkungen abzuwählen.
- Zug: Das Modul verfeinert das Klassifizierungsmodell basierend auf Benutzereingaben, einschließlich der Entfernung von Objekten oder der Neuzuordnung zu geeigneteren Klassen.
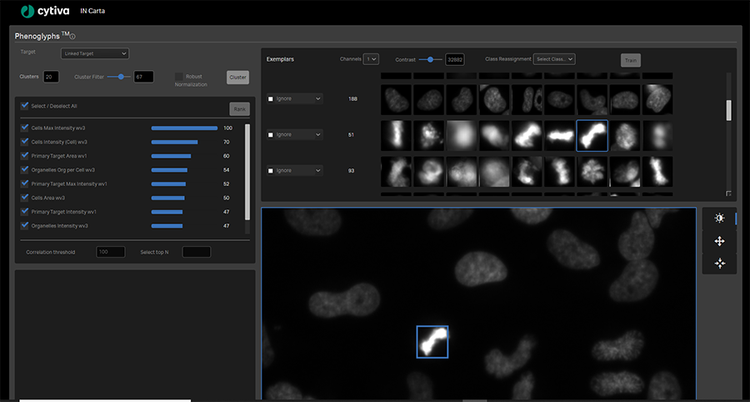
Schulung des Klassifizierungsmoduls für maschinelles Lernen nach Phenoglyphs
Als Benutzer müssen Sie nur eine kleine Anzahl an Beispielen aus jeder Klasse überprüfen und Anmerkungen hinzufügen, bevor das Phenoglyphs Modul das Modell auf den gesamten Datensatz anwendet. Dieser Ansatz minimiert den Bedarf an Benutzereingaben im ersten Schritt der Klassenzuweisung und spart so erheblich Zeit.
Vermutungen beseitigen
Einzigartig bei der IN Carta Software ist der erste unbeaufsichtigte Schritt, der in SINAP- und Phenoglyphs-Module integriert ist. Der unbeaufsichtigte Schritt erzeugt ein Anfangsergebnis, das iterativ optimiert wird, indem der Benutzer einfach die Entscheidung des Algorithmus bestätigt oder korrigiert. Dadurch entfällt die Belastung durch die Bestimmung eines praktikablen Ausgangspunkts für die Analyse und die Notwendigkeit, Parameter auf mühsame Weise zu optimieren. Durch die Kombination von SINAP und Phenoglyphs erleben Anwender einen durchgängigen Arbeitsablauf, der keine Erfahrung in der Bild- oder statistischen Analyse erfordert und für eine kürzere Zeit bis zu den Ergebnissen optimiert wird.
Erfahren Sie mehr über die Optimierung Ihres HCA-Arbeitsablaufs mit maschinellem Lernen. Sehen Sie sich unsere IN Carta Software-Seite an.